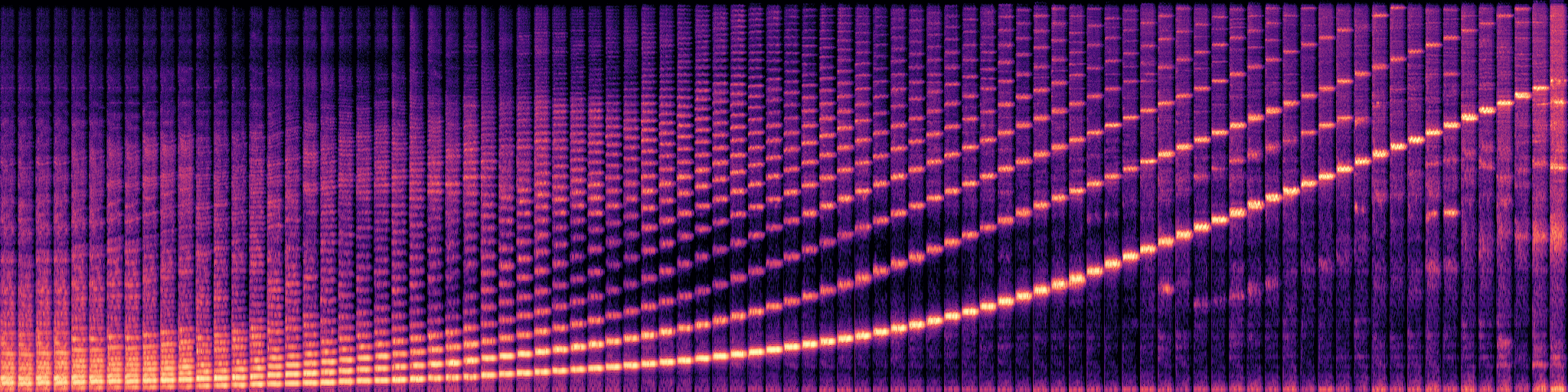
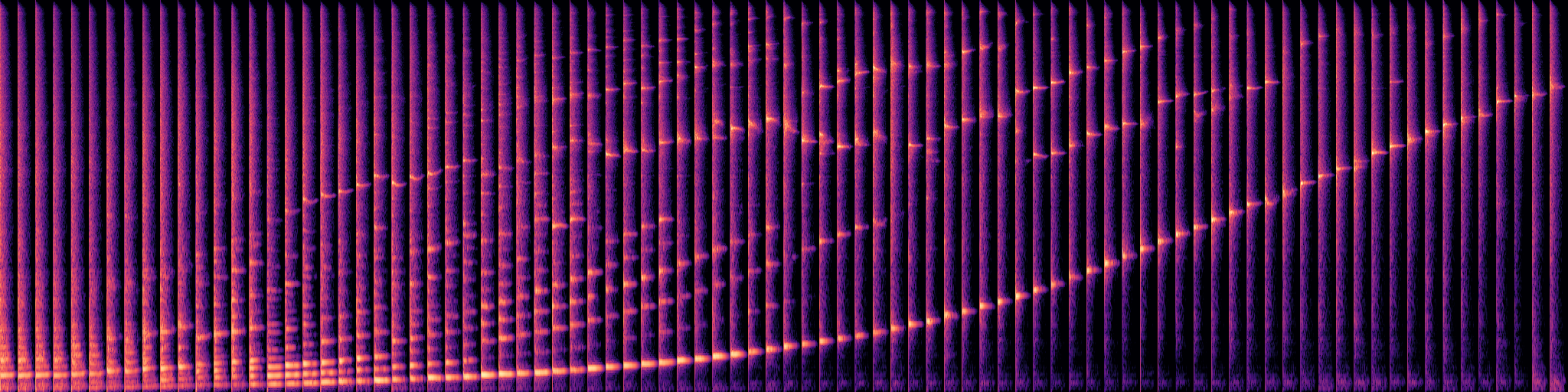
This web site demonstrates the audio examples of the paper titled GANStrument: Adversarial Instrument Sound Synthesis with Pitch-invariant Instance Conditioning.
GANStrument is a novel generative adversarial model for instrument sound synthesis.
Given a one-shot sound as input, it is able to generate pitched instrument sounds that reflect the timbre of the input within an interactive time.
By exploiting instance conditioning, GANStrument achieves better fidelity and diversity of synthesized sounds and generalization ability to various inputs.
In addition, we introduce an adversarial training scheme for a pitch-invariant feature extractor that significantly improves the pitch accuracy and timbre consistency.
The following examples play the Prelude of Suite No. 1 in G major, BWV 1007, J.S. Bach, with GANStrument-generated sounds.
Two one-shot sounds are used as inputs for each example, and synthesized timbre is gradually varied over time based on the interpolation in the latent space, where the interpolation ratio is incremented by 0.1 every bar.
Synthesized results demonstrate that GANStrument is able to generate instrument sounds with accurate pitch that reflect input timbres, and smoothly interpolate multiple sounds.
Note that, in contrast to end-to-end music synthesis, instrument sound synthesis with GANStrument enables independent control of MIDIs and timbre, which is compatible with typical production flows in the music industry.
Flute to Brass
input 1
input 2
interpolation (input 1 to 2)
Flute to Keyboard
input 1
input 2
interpolation (input 1 to 2)
Organ to Guitar
input 1
input 2
interpolation (input 1 to 2)
Mallet to Reed
input 1
input 2
interpolation (input 1 to 2)
Conditioning Comparison
To validate the proposed approach, we trained two class-conditional GANs as strong baselines: the first model was conditioned on pitch, and the other was conditioned on both pitch and instrument category (using 11 NSynth instrument categories).
Note that we used the same architecture and training parameters for these models for fair comparison.
The following examples show the interpolation in the latent space.
For baseline models, we projected the input onto the latent space by the hybrid GAN inversion that uses both an encoder and optimization as described in the original paper.
We trained both our model and baselines on the NSynth dataset [1]. The Good-sounds dataset [2] was not seen during training.
Note that NSynth inputs were taken from validation or test sets.
The following results demonstrate that the baseline models struggle with inverting the inputs and completely fail to mix two sounds.
On the other hand, GANStrument smoothly interpolates two timbres with accurate pitch.
Keyboard and Brass (Nsynth, Fig. 2 in the original paper)
conditioning
input 1
100:0
75:25
50:50
25:75
0:100
input 2
pitch w/ enc.+opt.
pitch + instrument w/ enc.+opt.
pitch + instance (ours)
Bass and Mallet (NSynth)
conditioning
input 1
100:0
75:25
50:50
25:75
0:100
input 2
pitch w/ enc.+opt.
pitch + instrument w/ enc.+opt.
pitch + instance (ours)
Vocal and Guitar (NSynth)
conditioning
input 1
100:0
75:25
50:50
25:75
0:100
input 2
pitch w/ enc.+opt.
pitch + instrument w/ enc.+opt.
pitch + instance (ours)
Clarinet and Cello (Good-sounds, unseen)
conditioning
input 1
100:0
75:25
50:50
25:75
0:100
input 2
pitch w/ enc.+opt.
pitch + instrument w/ enc.+opt.
pitch + instance (ours)
Saxophone and Trumpet (Good-sounds, unseen)
conditioning
input 1
100:0
75:25
50:50
25:75
0:100
input 2
pitch w/ enc.+opt.
pitch + instrument w/ enc.+opt.
pitch + instance (ours)
Flute and Violin (Good-sounds, unseen)
conditioning
input 1
100:0
75:25
50:50
25:75
0:100
input 2
pitch w/ enc.+opt.
pitch + instrument w/ enc.+opt.
pitch + instance (ours)
Feature Extractor Comparison
We conducted an ablation study to evaluate the effectiveness of the proposed pitch-invariant feature extractor.
For comparison, we trained an instrument identity classifier without the pitch-adversarial loss as the baseline feature extractor.
The following examples show mel-spectrograms of 88 pitches generated with the input of the NSynth and Good-sounds datasets.
Note that we fixed the noise vectors across 88 pitches.
These results demonstrate that the feature extractor without adversarial training scheme produced inaccurate pitches and timbre inconsistency.
In contrast, the pitch-invariant feature extractor with our adversarial training scheme produced stable pitches with timbre consistency.
Keyboard (NSynth)
feature extractor
input
88 pitches
w/o adv. training
w/ adv. training
Vocal (NSynth)
feature extractor
input
88 pitches
w/o adv. training
w/ adv. training
Mallet (NSynth)
feature extractor
input
88 pitches
w/o adv. training
w/ adv. training
Clarinet (Good-sounds, unseen)
feature extractor
input
88 pitches
w/o adv. training
w/ adv. training
Cello (Good-sounds, unseen)
feature extractor
input
88 pitches
w/o adv. training
w/ adv. training
Saxophone (Good-sounds, unseen, Fig. 3 in the original paper)
feature extractor
input
88 pitches
w/o adv. training
w/ adv. training
Additional Examples
Non-Instrument Sound Inputs
The following examples show synthesized results with the input of non-instrument sounds.
The synthesized sounds reflected the input timbres and produced stable pitch like musical instruments.
These results demonstrate that GANStrument has generalization ability to non-instrument sounds to some extent and is able to exploit a variety of sound materials to design the timbre as the traditional samplers do.
Rooster Chicken (Fig. 4 in the original paper)
input
pitch 48
pitch 55
pitch 60
pitch 67
pitch 72
Water Drop (Fig. 4 in the original paper)
input
pitch 48
pitch 55
pitch 60
pitch 67
pitch 72
Firework Explosion
input
pitch 36
pitch 43
pitch 48
pitch 55
pitch 60
Cat Meow
input
pitch 60
pitch 67
pitch 72
pitch 79
pitch 84
Drill
input
pitch 60
pitch 67
pitch 72
pitch 79
pitch 84
Latent interpolation
The following examples show the interpolation in the latent space.
Their inputs included harmonic instrument sounds, percussive sounds, and non-instrument sounds as well.
These results demonstrate that GANStrument is able to smoothly interpolate multiple sounds with stable pitch and enables users to freely explore the desired timbre in the latent space.
Organ and Guitar
input 1
100:0
75:25
50:50
25:75
0:100
input 2
Reed and Mallet
input 1
100:0
75:25
50:50
25:75
0:100
input 2
Keyboard and Flute
input 1
100:0
75:25
50:50
25:75
0:100
input 2
Brass and Organ
input 1
100:0
75:25
50:50
25:75
0:100
input 2
Reed and Hi-hat
input 1
100:0
75:25
50:50
25:75
0:100
input 2
Bass and Tom
input 1
100:0
75:25
50:50
25:75
0:100
input 2
Guitar and Cat Meow
input 1
100:0
75:25
50:50
25:75
0:100
input 2
Reed and Drill
input 1
100:0
75:25
50:50
25:75
0:100
input 2
Bonus Track
We tried making loop tracks by ourselves using GANStrument.
Loop Track 1
The following example consists of 3 tracks for which we use GANStrument-generated sounds and the accompaniment track of drum.
Note that the interpolation ratio of the 3 main tracks varies over time (0.0, 0.1, 0.2, …, 1.0) and we do not use GANStrument-generated sounds for the accompaniment track.
track
input 1
input 2
interpolation (input 1 to 2)
Track 1: melody (mallet to reed)
Track 2: arpeggio (flute to keyboard)
Track 3: chord (organ to guitar)
accompaniment (not generated)
N/A
N/A
Mixing result
Loop Track 2
The following example consists of 4 tracks for which we use GANStrument-generated sounds and the accompaniment track of keyboard and drum.
Note that the interpolation ratio of the 4 main tracks varies over time (0.1, 0.2, 0.5, and 0.9) and we do not use GANStrument-generated sounds for the accompaniment track.
track
input 1
input 2
interpolation (input 1 to 2)
Track 1: bass (bass to kick)
Track 2: melody 1 (flute to brass)
Track 3: melody 2 (organ to guitar)
Track 4: arpeggio (string to marimba)
accompaniment (not generated)
N/A
N/A
Mixing result
References
[1] J. Engel, C. Resnick, A. Roberts, S. Dieleman,
M. Norouzi, D. Eck, and K. Simonyan, “Neural audio
synthesis of musical notes with wavenet autoencoders,”
in Proc. ICML, 2017.
[2] O. Romani Picas, H. Parra Rodriguez, D. Dabiri,
H. Tokuda, W. Hariya, K. Oishi, and X. Serra, “A
real-time system for measuring sound goodness in instrumental
sounds,” in Audio Engineering Society Convention
138, 2015.